Big Bird: Transformers for Longer Sequences

寫在前面
當看到另一個芝麻街人物的時候,你可能會意識到:「啊,這又是一個 Google 出的 BERT 系列模型了。」
是的,這是 Google 最新出的論文,討論如何解決 BERT 在處理長文本時碰到的一些阻礙。雖然目前 (2020/10/26) 還只在 arXiv 上出現,但考量到它五十多頁的篇幅,應該是打算發在頂級期刊上的。
而為什麼「用 BERT 處理的長文本」是個重要的事情,是因為如果你有一點點用 BERT 的經驗,你就會知道一般 BERT 可以接受的最大文本長度通常是 512,再長就沒辦法塞進記憶體一次處理了。但在一些諸如 QA, IR 等等較大且繁瑣的 NLP 問題中,512 可能連一份文本長度的一半都不到,因此嚴重限制了 BERT 在這類問題上的表現。
其實關於長文本在 BERT 上處理的相關方法很多 (Ex: Longformer, Reformer, …),選擇討論這篇論文的原因,是它對於這一類的方法給了很好的理論說明,甚至完整的數學證明等等,對於如何理解 Attention 相關的各項技巧也有很有趣的 insight。此外,它處理實驗的手法跟邏輯也很值得我們學習,相當完整而全面。
另外,由於 Medium 上不能直接打 LaTeX(翻桌),文句中插入的數學符號可能會有點醜,有時候受不了我就直接從 Hackmd 上截圖了,請大家見諒QAQ
Agenda
- Transformer 是什麼?
這邊會簡單介紹 Transformer,並提及一些重要的組成元素。
- 讓你的 BERT 快一點
這部分會提及一些過去在 BERT 上處理長文本的技巧,還有這篇論文提出的方法等等。
- 為什麼 Sparse Attention 是處理這類問題的好方法?
這裏主要討論論文中的理論證明部分。
- 實驗
因為實在是太長了,就做個列表,順便走一遍它做實驗的邏輯。
- Reference
放一些我過程中參考的論文和文章
Transformer 是什麼?
首先要知道的是, BERT 在當前的 NLP (自然語言處理) 領域中,可以說是最重要的模型,沒有之一。許多下游任務的公開 Leader Board 上 (Ex: 文本分類、QA、NER、IR, …),前五十名不是 BERT 就是它的各式兄弟姊妹模型。
而所謂的 BERT 就是把 Transformer 這樣的一個技術/神經網路層,一口氣疊十二層之後的成果。
我們會在這邊介紹一些 Transformer 模型的細節和關鍵元素,確保大家對這個模型有明確而完整的想像,有些東西也會在後面的介紹之後用到。
Attention Mechanism 注意力機制
TL;DR: 注意力機制是一種可以有效地幫我們「基於下游任務的表現」,找到加權平均合適的「權重」的方法。
注意力機制是 Transformer 類模型的核心,雖然之前可能有研究提過類似的概念,不過真正好好地整理、取得成果的一般認為是來自 Google 2017 年的 “Attention is all you need”。Transformer 這個名字也是在這篇文章後開始被廣泛使用。
關於 Attention 機制的例子,可以先看看下面這張圖:

假設我們今天想要做一個「跟犯罪有關」的「文本分類模型」,而我們已經有了每個單詞的 embedding (aka 代表向量)。
這時候直覺的做法,應該是想辦法從這些 word embedding 中,生出所謂的 sentence embedding 或 document embedding,再把它們丟給另一個分類模型去分類。
那麼,最直接簡單從 word embedding 生成 sentence embedding 的方法是什麼呢?
沒錯,是「算數平均數」!
把句子中每個字的 embedding 加起來平均,應該是我們能最直接想到的方法。
但如果你有稍微做過類似研究,或是出於你的常識,應該要知道的是,每個詞在句子中的重要性應該不太一樣,而這個重要性跟你想做的 task 也有關。
以上述的例子來說,因為我今天想做的是與「犯罪」相關的文本類型,那麼在這樣的句子中,「傳喚」與「到案」兩個詞的重要性,應該會比其他單詞要重要的多。
那麼相應的,採用「加權平均」代替「算數平均」應該就很合理。
但這時候就會產生另一個問題:
加權平均的權重該怎麼決定呢?
這就是 Attention 機制重要的地方了。
Attention 機制就是一個可以給予每個詞不同權重的方法,
它會基於下游任務的表現,來決定我們應該要專注在哪些單詞上,
並讓它們獲得更高的權重。
上面的範例中可以看到,我的 Attention 模型的確給了「傳喚」跟「到案」更高的 attention score。
注意力機制是怎麼運作的
TL;DR: Attention 的核心就是去算內積。
有興趣做更詳細了解的人,可以去參考
The Illustrated Transformer 我圖也是拿他的XD
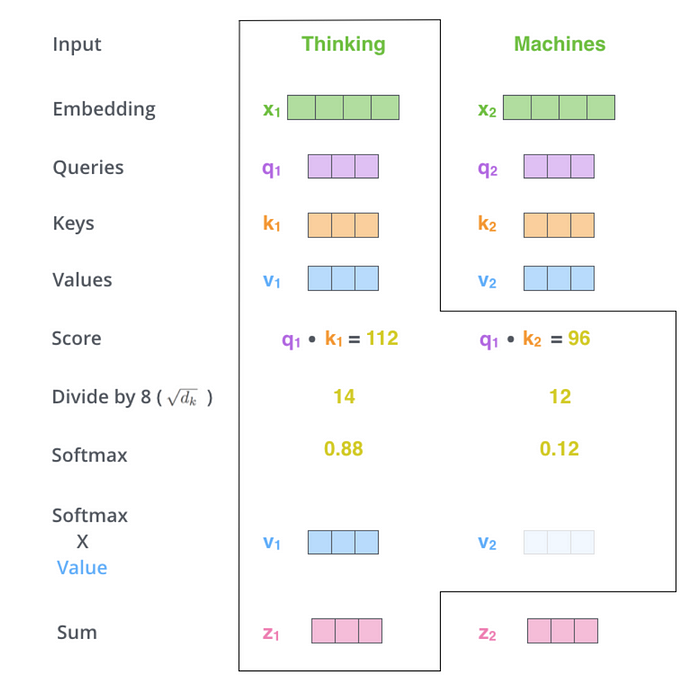
現在,讓我們來走一次 Attention 算分數的流程。
首先,你應該要知道的是,所謂的 “Attention Mechanism” 其實就是在算內積,算出來內積分數大的,權重就高,反之亦然。

其中,Q, K, V 分別代表 Queries, Keys 和 Values。
那實際上所謂的 “Attention Score” 就是把 Query 向量跟 Key 向量去做內積得出來的。
比如在這個例子裏,假設我今天想得到 「從 Thinking 看 Machines」的分數,就把 “Thinking” 的 query vector q₁拿去跟 “Machines” 的 key vector k₂ 去做內積。 「從 Thinking 到 Thinking」 的分數也是同理。
那假設我今天拿到了這兩個分數 (112 & 96),就可以很直覺地把它丟給一個 softmax 函數,來得到它們各自的權重。(不知道什麼是 softmax 的同學,可以參考這邊的 連結)
這個權重大家可以簡單地把它想成我們加權平均的權重。
拿到權重之後,當然要快樂的找個東西火大展開來算加權平均,而 value vector 就是我們拿權重去乘的對象。把權重乘以各自的 value vector 之後加起來得到的向量,就是最後的輸出向量。
值得注意的是,因為我們是拿 “Thinking” 的 query 出來算,這個合成的向量就是 “Thinking” 的輸出向量。
所以這時候 Query, Key 跟 Value 的角色就會比較明確了:
假設句子裏有 A, B, C 三個單詞。
如果我今天想找 A 的輸出向量,就把 A 的 query vector 拿出去跟 A, B, C 的 key vector 去算內積,拿到 attention score 之後,用 softmax 算出三個權重,再分別乘以 A, B, C 的 value vector 之後加起來,就會得到 A 的輸出向量。
Query 負責出去找別人的 Key 去算內積跟權重。
Value 就拿來跟這個權重相乘,負責當每個詞的代表的感覺。
這樣的過程會讓我們的每個單詞,在經過這樣的 Attention Layer 之後,輸出的向量都會同時考量到文章裏的其他單詞。
這個 idea 的重點是什麼呢?
就是 「在考慮前後文的情況下,如果 A 跟 B 一起出現,那麼他們的 Embedding 應該要一起被考慮。」
其實類似的這種考量 Co-Occurence 的技巧,你可能也聽過,就是有名的 Word2vec,而且也來自 Google。
但傳統的 Word2vec 模型通常是把這個「一起出現」的範圍,侷限在一個固定的 window size,比如說周圍的三個詞、五個詞之類的,而 Attention 想做的則是去擴展這個範圍,讓「出現在同一篇文章的詞都可以被互相考慮到」。
最後補充一下:

做這個動作的意義是,如果不除這個數字,在維度一高的時候,softmax 算出來的數字之間落差就會很大,會造成所謂的 “Gradient Explosion” 或是 “Gradient Vanish” 現象,對模型的表現有很大的負面影響,這時候除一下維度的根號,數值大小就會比較好控制。
Attnetion 相關的數學式:
TL;DR Query, Key, Value 的生成只是把 Input 過一個 Linear Transformation
基於完整性的理由,這邊附上 Attention 的數學式,以及 Query, Key, Value 是怎麼基於 Input Embedding 生成的。
可以看到也不過就是簡單的 Linear Transformation,套個矩陣乘法而已。
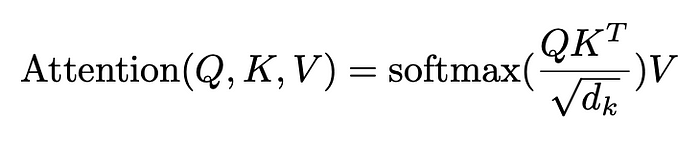
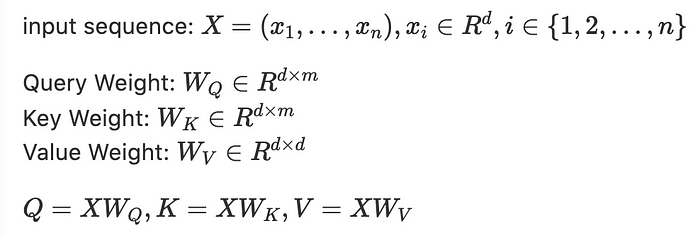
雖然這邊是用右乘,但其實用左乘也可以,只差一個轉置。 Google 相關的論文幾乎都是用右乘,因為這樣在矩陣乘法中,可以一次拉一條 row 出來算,而一條 row 正好是一個詞的 embedding。
Transformer 裏的全連接層與殘差網路
TL;DR: BERT 裏的全連接就是 (線性轉換+平移) -> (Relu) -> (線性轉換+平移)。殘差網路則是拉一條線讓 layer f 的輸出等於 x+f(x)
在 BERT 相關的論文裏,你可能常常會看到所謂的 “fully connected layer” 跟 “feed-forward layer”,因為後面的證明會用到,所以我們姑且列一下,大概是長這樣的:
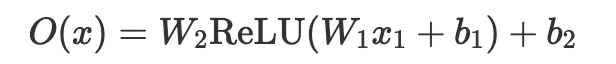
(想想左乘比較好看,還是左乘好了XD)
可以看到就是 Affine Transformation(線性轉換加平移) + ReLU + Affine Transformation。在 PyTorch 裏就是 Linear 加 ReLU 再加 Linear,Tensorflow 則是把 Linear 換成 Dense。
所謂的殘差網路 (residual net) 其實更重要。
假設我們今天有一個 input x,以及一個我們預計在這一層裏使用的 operation f,那這一層的輸出一般來說就是 f(x)。
但如果把它用 residual 的概念改造一下,寫成數學就會變成:
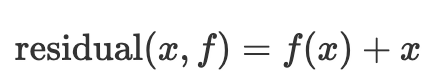
這個概念在 2015 年時,在 Deep Residual Learning for Image Recognition 這篇論文被提出,主要目標是解決在神經網路層數很多的時候,表現反而比層數較少的網路差的情況。
實際做起來會像這樣:
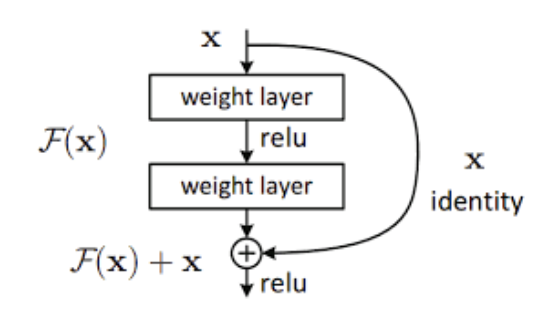
BERT 的模型在很多地方都使用了這個技巧。
Positional Encoding:
TL;DR: Positional Encoding 是要設計一個方法讓模型考量到文字的順序差異,且每個位置有不同的 Embedding。
Positional Encoding 的 idea 是這樣的:
在前面的 Attention 機制裏面,我們的確可以確保每個單詞的 Embedding 是基於詞本身以及 context,也就是說不同的字有不同的 Embedding,且同一個字視前後文的不同,也會有不同的 Embedding。
但基於前面我們提到的那些 Attention 流程,其實沒辦法考慮到「順序」的問題。
比如說「我餓了,我要吃飯。」這個例子裏,前述的 Attention 機制應該會給兩個「我」有一樣的 Embedding,因為它們既是同一個字,也有一樣的 context。同理,「我愛你」和「你愛我」的兩個「我」,也會基於同樣的理由,拿到一樣的 Embedding。
而解決這個問題的方法是,我們可以把句子裏的每一個單詞,除了表示單詞本身的 Embedding 之外,另外給一個基於它們「句子中位置」的 “unique” Embedding,並把它一起考量計算。
做到這件事的方法有兩種:
- 直接給定
一般的 Transformers 裏的 Positional Encoding 是這樣的:
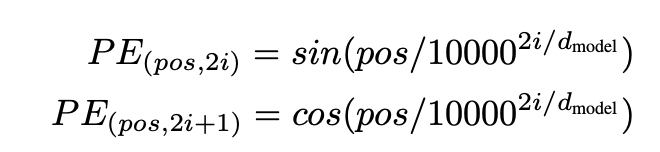
利用三角函數來確保每個不同的 position 有不同的 Embedding。
2. 訓練一個基於 Position 的 Embedding
其實這個方法在 “Attention is all you need” 也有被測試過,但因為跟上面結果差不多,就直接用給定的比較簡單了。
有趣的是,後來許多跟 Transformers 的數學證明有關的 paper 都喜歡用下面這種,因為可以 train 的話有可變性,這樣證明比較好湊XD
單層的 Transformer (只有 Encoder)
TL;DR: Transformer = Attention -> residual connection -> fully-connected -> residual connection
其實當初在 “Attention is all you need” 裏,Encoder 跟 Decoder 都有被提出來,只是 BERT 只選用了 Encoder 部分,這裏就為了篇幅只講 Encoder 部分。
(其實只有一些細節的差異,想了解的同學可以參考 T5 之類同時使用兩者的模型)
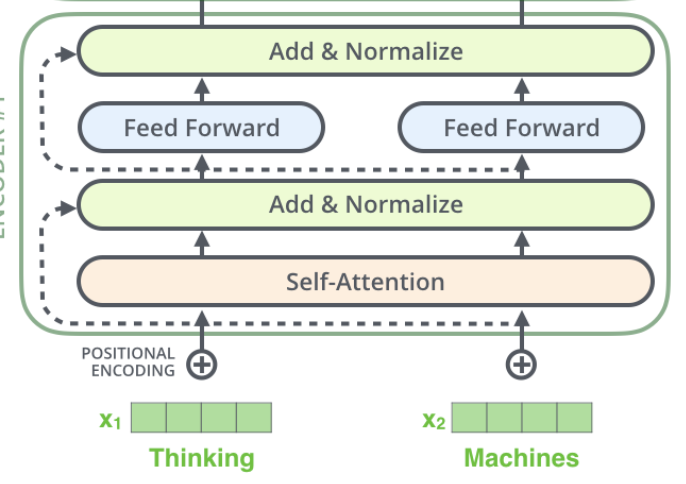
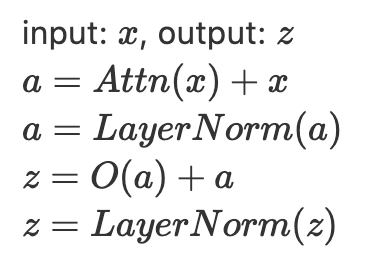
首先把單詞的 Embedding 跟它的 positional encoding 加起來當成 input x,過一層 Attention + residual,normalize 一下,再過一層 feed-forward / fully connected + residual,再 normalize 一次,這就是一般所謂的 “Transformers” 的一層操作了。
現在我們介紹完了基礎的 Transformers 概念,該進入這篇論文想要討論的主題了。
讓你的 BERT 更有效率
我們現在大概知道什麼是 Transformer 了,接著要看看這篇文章想解決的問題是什麼、源自於哪裡,以及一些現行的和這篇論文提出的解決方案。
問題說明:
TL;DR: 將 Attention 的概念用 Graph 去表示,可以發現一般 Attention 的計算複雜度是 n²,直覺的解決方式是少算一點。
關於這篇論文想要解決的問題,它給了一個很有趣的 insight,將 Attention 的概念和 Graph 做了連結,我們不妨從這邊先開始:
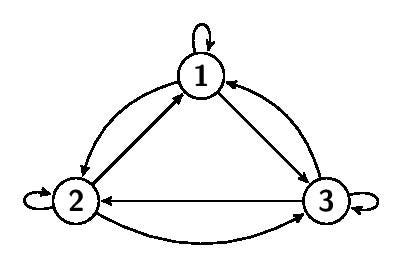
首先,給定一個長度為 n 的句子,並把它們當成 Graph 上的 n 個點。
接著,我們把所有「從某個單詞 A,對某個單詞 B 做 Attention」的情況,都在 Graph 上建一條「從 A 點到 B 點」的邊。
由於在一般的 Attention 裏面,單詞間都是彼此會做 Attention,因此應該可以造出一個點跟點「全部」彼此互相連接的有向圖,而且從某一點到任意另一點都只有一條邊。也就是所謂的 complete directed graph。
這時候問題來了,請問在這樣的一張圖上,總共會有幾條邊呢?

或者假掰一點,可以說這樣「在長度為 n 的句子裏,算 Attention 的計算複雜度,是 O(n²)」。
這個就是這篇論文想解決的問題了。
而我們在最前面提過,一般 BERT 可以接受的最大文本長度通常是 512,因為在一次的 Attention 中,就需要使用 512² 的運算時間跟資源,這是對顯示卡記憶體和效率的很大負擔,何況你還有 12 層。
而關於怎麼解決這樣的問題,我們可以回來看看這張圖:
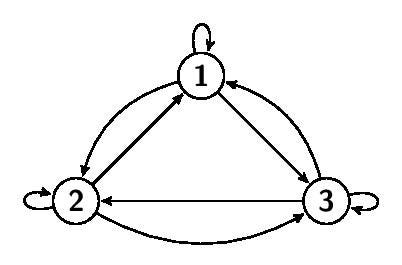
會需要這麼多的運算資源跟時間,是因為我們把圖上的每個點都彼此連接,亦即每個單詞兩兩之間都要做兩次 Attention,而如果我今天想偷雞,想要偷偷摸摸的少算一點,最直接的想法應該就是「想辦法擦掉一些不重要的邊」,也就是這篇論文整合出的理念:“Sparse Attention”。
透過「擦掉一些邊」的方式,我們讓一些單詞彼此之間不需要做 Attention,比如去限制每個點最多只能連出 d 個邊,且 d<<n,這樣運算成本自然就減少了,複雜度也會從 O(n²) 變成 O(d*n)。
Sparse Attention 的例子
這邊我想介紹一些利用 Sparse Attention 概念的研究。
我們前面提過,Sparse Attention 的核心理念就是讓「不重要的邊就不要算 Attention」,而這些研究的差別通常就在於它們怎麼去定義「不重要的邊」這件事。
Longformer
TL;DR: Sliding Window Attention + Global Attention
我們從 Longformer 先開始。
這篇論文由 Allen Institute 的科學家們提出。
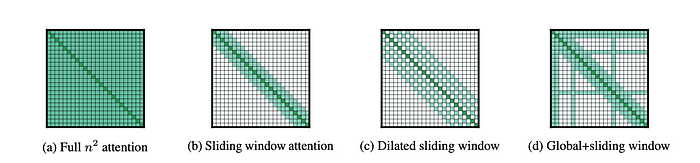
最左邊的 (a) 是一般的 Full-Attention 的示意圖。
可以想像橫軸是 key vector,縱軸是 query vector,index 則代表這是句子中第幾個字。
他們首先考量的,是在考量特定單詞 A 的時候,它「周圍」的單詞,應該會比其他單詞對 A 的影響大,因此首先就只讓靠近的單詞們彼此做 Attention(aka 去算內積)。也就是 (b) 的 Sliding Window Attention。
那這時候就會有人擔心,如果只考慮連續的 window,可能會受限於 window size,沒辦法考量到距離稍遠,但也很重要的那些單詞,於是它們就讓 window 間有一些「跳過」的行為,成為 ( c ) 的 Dilated Sliding Window。
另外一個重要的想法是,他們認為有一些單詞,在文章中的地位和其他單詞相比更為重要,比如 BERT 裏常用的 [CLS], [SEP] 兩個 tag。於是他們決定要讓每個單詞都跟那些特殊的 tag 做 Attention,這些 global tag 也會跟每個單詞都做 Attention,稱為 Global Attention。
除了這些特定的 tag,global token 還可以基於下游任務來事先決定。比如在維基百科相關的 QA 問題中,他們會讓文本裏的「前面 128 個 token」都是 global token,因為在維基百科的文章中,第一段的前面幾句話通常就是整篇文章的重點和大意,比其他段落扮演更重要的角色。
而把這樣的 Global Attention 和 Sliding Window Attention 結合起來,就會變成圖(d)了。
Big Bird
TL;DR: BigBird = Longformer + Random Attention
Big Bird 的模型部分,只是把 Longformer 加上一個 Random Attention (給定一個機率,讓兩個單詞間彼此做 Attention)而已。
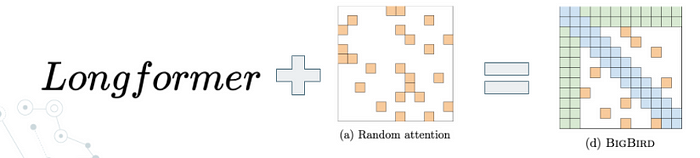
聽起來很 low,但本來它的亮點就在它怎麼用數學證明這個 idea 在理論上有效,以及完整的實驗而已。
畢竟 Longformer 對於理論部分少有著墨。
Reformer
TL;DR: Reformer = Locality Sensitive Hashing + RevNet
跟模型部分簡潔粗暴的 Longformer 和 Big Bird 相比,Reformer 使用了相對精巧複雜的方法。主要分成兩個部分來介紹。
這篇論文來自 ICLR 2020。
1. Locality Sensitive Hashing
TL;DR: LSH = CLustering + Hash Table by Locality
這個 idea 是基於以下的兩個事實出發的:
- 在一般的 BERT-based word embedding 裏,0 非常多。
- 我們通常會在 Attention 最後加一層 softmax 函數,而在經過 softmax 函數之後,整個值會被 input 裏比較大的幾個數字控制。
第二點對某些同學來說,可能稍嫌不夠直觀。
我們先來看看 softmax 的定義。
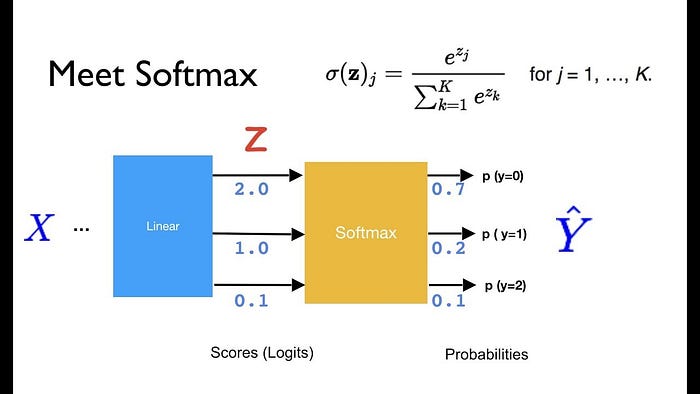
假設我丟 1~10 進去,輸出也會有 10 個,每個值是該數字取自然指數,除以全體的自然指數和。
接著我們來看看把 1~10 丟進 softmax 的結果。
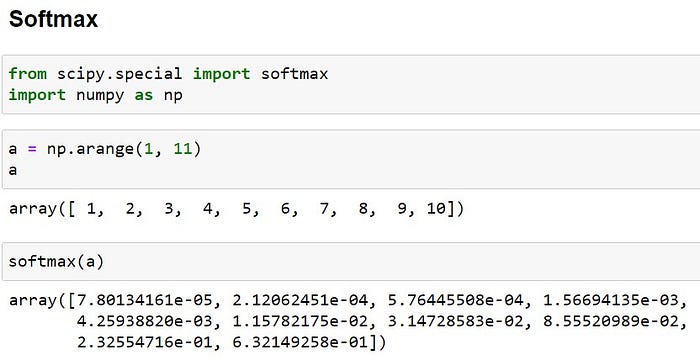
可以看到跟 9, 10 的結果相比,其他數字的輸出小到趨近於 0,這就是上面的第二點想表達的事情了。
我們的 Attention 講白了就是在算內積,而內積因為之後接了 softmax,造成內積比較小的那些值,對於模型的影響趨近於 0。那作為一名有理想有抱負的工程師,忽略那些內積小的,甚至從一開始就不去算那些小內積,不也是一件理所當然的事情嗎?
那假設我們有一堆不同方向的單位向量,請問是彼此靠近的那些向量內積大,還是距離遠的那些向量內積小呢?
當然是都對XD
總之,我們只想要大內積。而因此,如果我有一個單詞 A,我應該只讓它跟 Embedding 相近的那些單詞去做 Attention 就好,這樣才是最有效率的。
這時候問題就來了。
- 我該怎麼樣快速地算出哪些 Embedding 彼此靠近呢?
- 算出來之後怎麼樣快速地查詢這些結果呢?
首先,如果這時候我還需要兩兩一組地去算這些內積,不就跟原本一樣,回到 O(n²) 的老路上,這樣豈不是脫褲子放屁嗎?因此,找一個相對有效率的方法把相近的 Embedding 彼此分組很重要,犧牲一點精準度也沒關係。
這種方法是不是跟我們常常說的 clustering 很像呢?
另外,為了避免 O(n) 的搜尋複雜度,我們 Computer Science 不是常常使用 O(1) 的 Hash Table 來處理嗎?
簡而言之,LSH (Locality Sensitive Hashing) 的概念,你可以想像成 Clustering + Hash Table。
Reformer 中,LSH 的操作細節:
首先, LSH 跟一般 Hash Table 的最大差別在於,一般的 Hash Table 是透過一個隨機的 Hash function 來決定每個點該被分配到哪個 bucket,但 LSH 會把相近的點分到同一個 bucket。
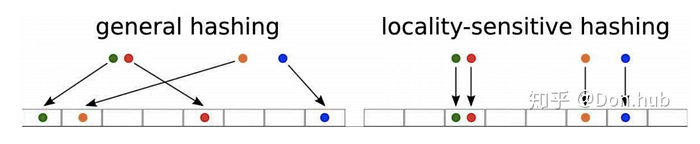
接著,為了能有效率地區分哪些向量彼此靠近,LSH 使用了一種稱為 “Random Projection” 的技巧。
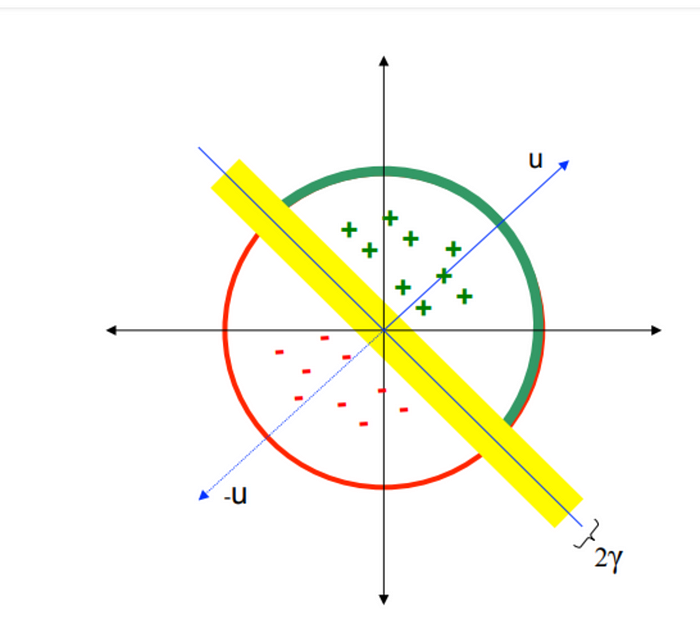
這個方法的概念是這樣的。
首先,假設我們在二維平面上有一坨點,並且用一個隨機的向量 ( 黃色那條 ) 把這坨點分成兩群。這時候,我們應該可以粗淺地假設:「被分在同一群的點會比較近,分在不同群的點會比較遠。」
至於這個假設為什麼會成立,是因為在高維空間中,點跟點彼此之間都超遠的,因此雖然我們不能確定分在同一群的點是不是很近,但不同群的點之間,大概有高機率會距離比較遠。
這時候,我們應該怎麼快速地,知道哪些點會分在同一群呢?
讓這些點跟黃色向量的法向量 u 去算內積!
內積為正是一群,為負就是另一群。
雖然還是在算內積,但我們只需要 O(n) 就可以完成分群了。
這邊我們稍微看一下程式的實作,可能會讓大家更容易理解:
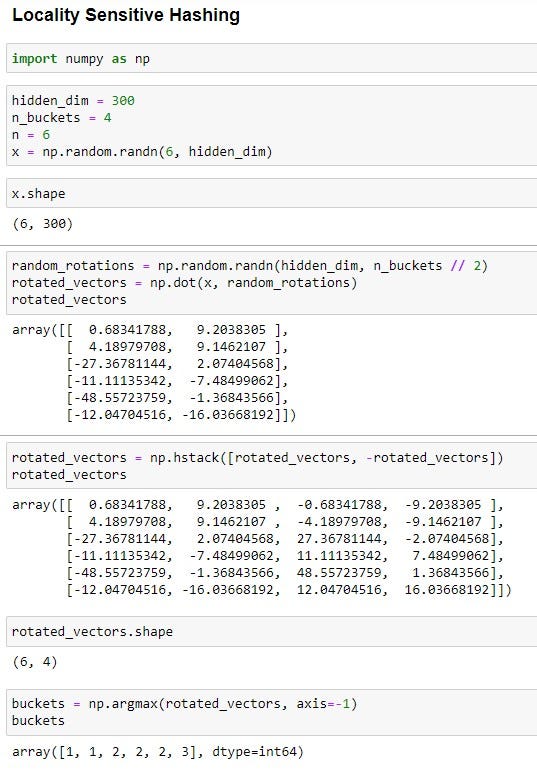
假設一個長度為 6 的句子,代表這句話裏有 6 個 token,我們的目標是把這些 token 分成 4 組,也就是要從這 6 個 token 的 Embedding 中湊出一些向量來表達分組這件事。
而由於我們的 token embedding 維度是 300,sentence embedding x 的 shape 很自然是 (6, 300)。
這時候因為我們想把所有 token 分成四組,所以開一個 shape 是 (300, 4/2) 的隨機矩陣,維度的順序是因為考量到等下要做內積/矩陣乘法的關係。
乘完之後因為句子長度是 6,而隨機矩陣裏有 2 條長度為 300 的向量,所以會乘出 6∗2 個內積。之後把這 6*2 個內積取正取負之後串在一起,就會變成 6∗4 個內積。
這時候把每一個 row 的內積串起來,就會得到 6 條長度為 4 的向量,
把每一條最大值的 index,直接當成分組的 index 之後,就成功把這 6 個 token 分成 4 組了!
LSH 的操作細節:
TL;DR: 「我們不解決問題,我們解決出問題的 bucket。」
先來看一下這張圖:
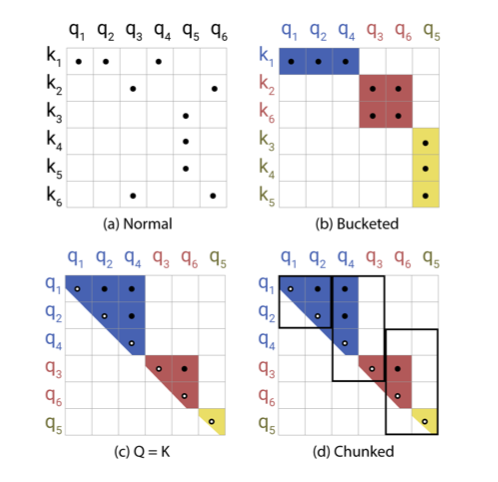
(a) 是我們一般的 Attention 機制,橫軸是 query,縱軸是 key,圖上的黑點是兩者內積不是 0 的部分。
(b) 是簡單套個 LSH 之後的結果,將 query 跟 key 重新排序之後分 bucket (用不同顏色表示不同 bucket),只要計算不是 0 的部分就好了。
但這樣會發生幾個問題:
- 因為在分 bucket 的時候是把 query, key 一起 cluster,所以可能會導致每個 bucket 中 query, key 數目不等,甚至整個 bucket 裏沒有 query/key 的情況。
- bucket 之間的總 vector 數不等。

(d) 則是為了解決 bucket 之間 vector 總數不同,導致實作困難和效率被最大的 bucket 控制的情況。透過強制讓每個 bucket 的 vector 總數一致,並預先決定該數目 (這個例子裏是 2),就可以簡單地搞定了。
我們不解決問題,我們解決出問題的 bucket。
但這樣當然會發生問題。
主要分成兩個:
- 同一個 bucket 裏有不同顏色 (原本分在不同組,距離較遠) 的 vector。
- 同顏色 (原本分在同一組,比較接近) 的 vector,不見得最後會在同一個 bucket。
解決的方法是依照下面這張圖:
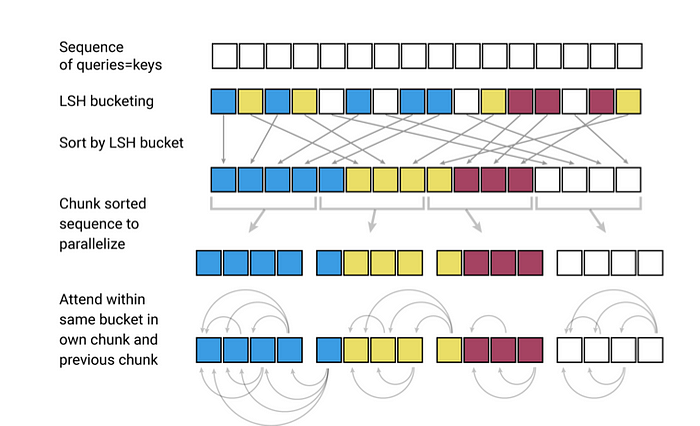
- 所有的 vector 只能跟同顏色的算內積 (不同顏色就算同 bucket 也不行)。
- 每個 vector 除了跟自己的 bucket,也可以跟隔壁 bucket 裏同顏色的算內積。
整體的概念有點像是透過 (d) 中相對工程的方法來解決效率跟實作上的問題,但為了模型表現再用上面兩個方法來降低 (d) 的負面影響。
依照上述過程,我們可以把 Big-O 從 O(n²) 降低到 O(n*2*|bucket|),因為 bucket size 通常遠小於序列長度 n,所以真的省蠻多的。
附一下一般 Attention 跟 LSH-Attention 的數學式,可以看一下實際上要怎麼操作:

上半部就是簡單的把 softmax 做個移項整理。
而下半部可以看到 LSH 比一般的 Attention 多減一個 m(j, Pᵢ),其中 Pᵢ 是指滿足上述條件,讓 qᵢ、kⱼ可以合法運算的那些 j 的集合。如果 i, j 可以合法計算,那 m(j, Pᵢ) 就是 0,跟一般的 Attention 一樣;而如果兩者運算不合法,帶回式子就會變成減掉無限大,整個值就會變成 0。
這樣就可以正確的只去計算我們想計算的那些 Attention。
RevNet:
TL;DR: 改良 ResNet 讓過程中的輸入輸出可以從最後一層的輸出回推。
總之先看一下數學式:
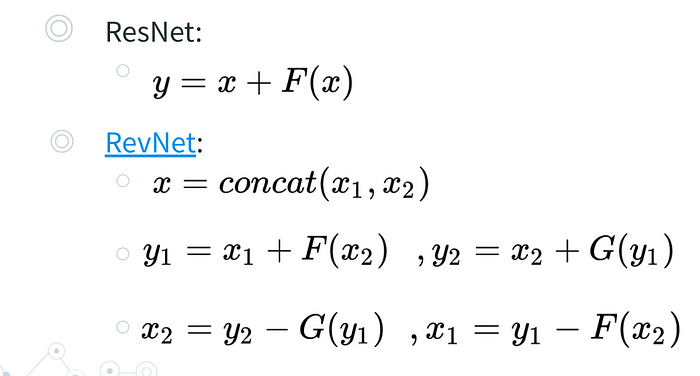
ResNet 雖然是個好棒棒架構,但跟一般的神經網路 ( y=F(x) ) 相比,沒辦法簡單的通過記住所有訓練參數 (可以想像成函數 F 的係數) 之後,直接去做 Backpropagation 的微分。(因為多了一個 x)
為了解決這個問題, ResNet 需要把過程中的「每一個 x 」都記下來,最後再去微分。但這樣就會浪費掉一大堆記憶體,所以 RevNet 透過一些小技巧,要想辦法讓模型只需要記住最後一層的輸出 y,就可以回推過程中所有的 x,來減低過程中記憶體的需求。

原始概念來自: RevNet
Reformer 透過巧妙的設計成功提高了 Attention 類模型的效率跟資源使用,其中許多方法的概念都很值得我們參考。
為什麼 Sparse-Attention 夠好:
TL;DR: 先證一般的 Transformer 夠好,再說明 Sparse-Attention 的 Transformer 也能符合這些條件。
原本的論文裏,這邊的證明分成:
- Sparse-Attention 的 Transformer 是個 Universal Approximator。
- Sparse-Attention 的 Transformer 是 Turing Complete。
但首先 Turing Complete 我不是特別熟,目前也沒有感覺到需要細究那部份的必要,就讓我先跳過吧,不然寫不完了XD
第一部分的證明中有些細節,我也還沒有完全搞懂,加上大部分人對於它應該興趣不大,我就從我理解的部分解釋吧,也許不太嚴謹或是跟原本的論文不太一樣,總之請多包涵XD
主要會分成三個部分:
- 什麼是 Universal Approximator?
- 一般的 Transformer 是 Universal Approximator 嗎?
- Sparse Attention 的 Transformer 是 Universal Approximator 嗎?
Universal Approximation Theorem
TL;DR: 一層且神經元數無上限的神經網路,可以擬合任何函數。
這是幾乎所有神經網路的數學理論基礎,定義可以參考 wiki



而且是不是跟前面提到的 BERT 裏的 feed-forward layer 一模一樣呢?

還是不太懂的同學,可以參考下面這張圖:
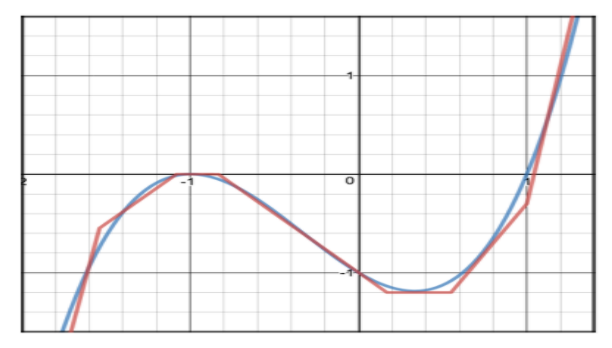
假設我們的目標函數就是圖上的藍線,那其中最有效的擬合方法,就是把 x 軸切成一塊一塊的,並且對於每一塊,用一條直線想辦法貼近裏面的藍線,就像圖上紅線在做的事一樣。

而所謂的 Universal Approximator 就是指某個模型可以依照它原生的架構,擬合任何的連續函數。相關的證明則多半利用上述的技巧,證明在給定任意連續函數 f 和誤差上限 ϵ 的情況下,你總是可以依照模型的演算法「兜」出某個 f′ 使得 f, f′ 的誤差小於 ϵ。
Transformer 是 Universal Approximator 嗎?
TL;DR: 證明概念就是 ϵ−δ trick 用三次 + Positional Encoding
原始證明來自:
Are Transformers universal approximators of sequence-to-sequence functions?
因為實在是太長太難了,簡單整理一下證明的流程:

這邊函數距離的定義是用:
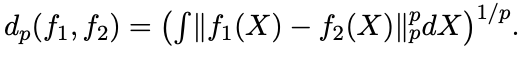

綜上所述,一般的 Transformer 是個 Universal Approximator。
Sparse Attention 是前面方法的特例:
TL;DR: Sparse Attention 要有 Global Attention 才能是 Universal Approximator。
前面證完了一般的 Transformer 是 Universal Approximator,接著 BigBird 這篇想要討論的就是,所謂的 Sparse-Attention,能不能也是個 Universal Approximator 呢?

這個 contextual mapping 的定義是這樣的:

首先當丟一串 token L 進這個 contextual mapping q 的時候,q 會確保輸出 q(L) 的每個 element 都不一樣。(在後續的證明過程中會利用到這個性質)
另外比較關鍵的就是第二項,對於每個不同的 L,輸出 q(L) 都會不一樣。(但不受排列影響。 ex: q(1,2,3)=q(3,2,1) )
這個性質其實跟我們期望的 Transformer 性質是一樣的,也就是基於文章中 context 的不同,希望 Transformer 能夠輸出不同的結果。
這件事在一般的 Transformer 中其實相對好達成,也容易證明,因為一般的 Transformer 會讓所有 token 互相算 Attention,可以簡單地考慮到所有的 context。然而, Sparse-Attention Transformer 核心理念就是要「少算一點 Attention」,要做到這點就相對困難了。
因此,在後續的證明上,BigBird 除了利用很多數學技巧,要從 Sparse-Attention「湊」出 contextual mapping 之外,也提到這樣的 Sparse-Attention 需要具備某個特殊性質,也就是在前半部分提過的 “Global Attention”。
Sparse-Attention Transformer 如果要成為 Universal Approximator 的話,就必須包含 Global Attention,讓某些特殊的 token 能跟每一個 token 都算到內積,這樣才能建立一個足夠好的 contextual mapping 並完成後續證明。
而為什麼會用到 Global Attention,可以利用前述 Graph 的概念做個粗略的解釋:
首先原生的 Attention 機制可以形成一個 complete graph,所有的 node 都會彼此連線,我在考慮任意的 node embedding 的時候,都可以收到其他所有 node 作為 neighbor 傳來的訊息。也就是說,我只需要一層 Transformer layer 就可以考慮到所有 node 的情況,建立起夠好的 contextual mapping。
然而,對 Sparse-Attention 來說,核心概念本來就是「擦掉某些邊」,因此圖可能會長成這樣:
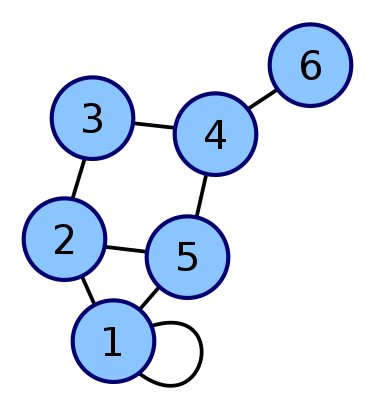
因此,如果 node (3) 想要考慮到 node (6) 的訊息,就必須要在第一層 Transformer 讓 node (4) 先看到 node (6) 的訊息,再讓 node (3) 在第二層收到 node (4) 中包含 node (6) 的訊息。沒辦法單靠一層 Transformer 完成。
(這個概念一般稱為 Message Passing,在 Graph Neural Network 中被廣泛應用,之後寫到相關 paper 時會再詳細解釋。)
甚至如果 node (4) 跟 node (6) 之間根本沒有連線,那 node (3) 就不可能考慮到 node (6) 的情況了。所以,為了確保任意的兩個 node 之間都能互相連通,有下面的結構就會很方便!
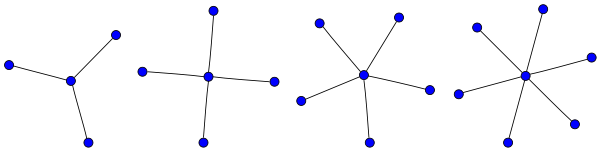
上面的圖我們稱為 Star Graph,表示對於一個總 node 數為 n 的 grpah,存在某個 node 使得其他所有 node 和它有連線。換成 Attention 的說法就是,在長度為 n 的句子中,存在一個 global tag 使得所有其他 token 都會和它做 Attention。
因此,一個有 Global Attention 性質的 Sparse-Attention 機制,代表它在轉換成 Graph 之後,也會存在類似的結構。
從上面的敘述可以知道,要讓 Sparse-Attention 具備有跟原生 Attention 一樣的能力,需要靠 Global Attention 和稍微多一點的層。
至於依據上述的推理怎麼去得到「多少層才是足夠的」這件事,請多給我一點時間研究一下,我就直接把論文的結論寫在下面了XD
做個小結論:
在字串長度為 n,誤差上限為 ϵ 的情況下:
- Transformer 好棒棒,是個 Universal Approximator 可以擬合任何連續函數。

這時候可能有同學會問,如果 Sparse-Attention Trnasformer 需要這麼多層,我們幹嘛不老老實實地用一般的就好呢?
首先,作為深度學習的基本認知(不管來自於證明或實驗),多層的堆疊肯定是有好處的,BERT 也告訴我們至少要疊個十二層才會夠厲害。所以在本來就會疊這麼多的情況下,sparse 跟 non-sparse 的差別就在 sparse 會比 non-sparse 稍微差一點。
然而,在同等記憶體下,一般的 BERT 只能最多吃到長度為 512 的文本,而 BigBird, Longfermer 卻能夠吃到 4096,這在 IR, QA 之類需要對長文章進行整合的下游任務中,就是一個超大的優勢了。
實驗:
實驗的主要目的,就是要說明這個模型/理論有效,大家可以參考一下當你有個富爸爸,不用擔心運算資源的時候,該怎麼做實驗XD
- Sanity Check:
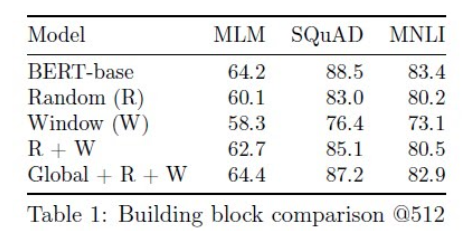
這個實驗把 BigBird 模型幾個性質對結果的影響做了展示,即使跟 BERT 同樣使用長度為 512 的文本也不會差太多,我覺得還蠻有說服力的。(沒有單獨的 Global 感覺是分數不高XD)
2. 下游任務測試:
BigBird 將模型測試在了以下幾個任務上:
- Pre-Training Task (MLM)
- Question Answering
- Document Classification
- Summarization
- Genomics Sequence
比較對象除了 BERT,還有這些任務上目前分數最高的幾個模型,嚇死人的完整,非常適合要做這些任務的同學們參考。
其中,跟一般 BERT 系列之間的比較,就是要說明在同等運算資源的情況下,能夠吃更長文本的模型,能夠在 performance 上佔到多少優勢。
至於同樣是處理長文本的 Longformer,比較重點就變成架構差異導致的結果不同了。
結論:
這篇文章給我們的幾個有用的 idea 是:
- 用 Graph 去重新理解 Attention 之間的關係。
- 處理長文本時,Sparse-Attention 系的方法值得考慮。
- 使用 Sparse-Attention 相關的方法時,Global Attention 都是個必須參考和比較的對象。
其實這篇論文證明部分的許多細節,對我們更深入理解 Transformer 也很有幫助,只是我還沒辦法完全理解每個步驟的用意,希望有機會未來再寫一篇來探討(合掌)。
References:
下列是我在閱讀過程中參考的一些論文和文章。
- The Illustrated Transformer. Jay Alammar, http://jalammar.github.io/illustrated-transformer/
- Bert: Pre-training of deep bidirectional transformers for language understanding. J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. arXiv preprint arXiv:1810.04805, 2018.
- Big bird: Transformers for longer sequences. Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. arXiv preprint arXiv:2007.14062, 2020.
- Longformer: The long-document transformer. I. Beltagy, M. E. Peters, and A. Cohan. arXiv preprint arXiv:2004.05150, 2020.
- Reformer: The efficient transformer. N. Kitaev, L. Kaiser, and A. Levskaya. International Conference on Learning Representations, 2019.
- 对Reformer的深入解读, 忆臻, https://zhuanlan.zhihu.com/p/115741192
- Universal approximation theorem. https://en.wikipedia.org/wiki/Universal_approximation_theorem
- (ε, δ)-definition of limit. https://en.wikipedia.org/wiki/(ε,_δ)-definition_of_limit
- Are transformers universal approximators of sequence-to-sequence functions? C. Yun, S. Bhojanapalli, A. S. Rawat, S. J. Reddi, and S. Kumar. International Conference on Learning Representations, 2020.
Useful links:
對於有需要實現 BERT 相關模型的同學,推薦以下兩個套件。
Transformers:
毋庸置疑的業界標準,有大量實作、更新快,稍微有點難用XD
https://github.com/huggingface/transformers
simpletransformers:
把 Transformers 再包一層的套件,超級好用,非常適合入門。缺點是拿 BERT Embedding 非常不方便,適合只需要處理下游任務的情況,如果要對模型實現細節進行調整等等,還是要老老實實用 Transformers。
https://github.com/ThilinaRajapakse/simpletransformers
特別感謝:
感謝實驗室的 Matt、小白、Jack 三位學長在前陣子辦了 NLP 讀書會,讓我能對 BERT 相關的模型和 IR, QA 等問題有更多認識,這篇文章中,關於 Reformer 的許多解釋和理解也都來自於 Matt 學長的分享。
而之前報的論文中留下的一堆問題,我一定會找機會查清楚 QAQ。